

Approaches to threat data exchange are currently in an active phase of formation and standardization. Today there are a couple of significant standards, namely, MISP and STIX, and entire assemblage of less significant ones that are less commonly used or considered deprecated, such as MAEC, IODEF, OpenIOC (Cybox), CAPEC, VERIS and many others. At that, a decent number of community feeds are still distributed in the txt or csv formats, as well as in the form of human-readable analytical summaries, bulletins, and reports.
This article deals with analysis of the generally accepted practices of data exchange about cyber threats, namely, specialized formats and general-purpose standards designed not only for threat intelligence (TI). At that, purely proprietary, rare and “reinvent-the-wheel” formats, as well as thematic blogs, news portals, messenger communities, and other TI sources in human-readable formats are left out of the scope of the present article. Today the focus is on machine-readable formats.
STIX format
Let’s start with STIX [1] standard. This standard is quite mature, since it has made ten-year way of development from version 1 to 2.1. It has good descriptive characteristics: thus it allows describing the threat in very detail, all its relationships, and technical artifacts. At that, the result will be suitable for both human and machine analysis. The standard is based on useful guiding principles that were followed throughout the development of STIX.
These are:
- Expressiveness;
- Flexibility;
- Extensibility;
- Automatibility;
- Readability.
STIX is actively being worked on, new editions are regularly released. The standard is supported by the OASIS organization, its Cyber Threat Intelligence committee unites more than 50 companies that know all the angles of working with TI. Therefore, the development of the standard is a way of generalizing the best practices, mistakes and conclusions that have been made by experienced specialists in this field.
STIX is a description language for TI data exchange and introduces a set of entities, as well as defines possible types of relationships between them. The standard is quite voluminous, so this article will not dive into all its details.
According to the specification, STIX is declared as serialize-agnostic, however in practice the JSON format is most often used. The schemas are in a public repository on GitHub. Any transport can be used for STIX, however, OASIS has taken care of this: the standard for TAXII transport is being developed in parallel with STIX, which uses HTTPS as a foundation.
STIX describes threat data as a connected graph, where nodes are SDO (STIX Domain Objects), while SRO (STIX Relationship Objects) are edges.
As SDO, STIX defines the following malicious objects:
- Attack pattern – describes the approach (TTP) that the attacker used to hack his target. This entity is used to classify attacks, generalize specific attacks according to the patterns they follow, and provide detailed information about how attacks are executed.
- Malicious campaign – describes a sequence of malicious behavioural signs that occur over certain time periods.
- Course of action – describes the measures to be taken to avoid or resist an attack.
- Identity – describes persons, organizations, or their groups.
- Indicator – describes technical malicious artifacts that can be used to detect malicious activity (for example, IP addresses, domain, hashes, and registry keys).
- Intrusion set – describes a set of behavioural signs and resources with common properties that are most likely controlled by one organization. The key difference from Campaign is that the latter usually represents malicious activity aimed at a specific target, and lasts for a limited period of time, whereas Intrusion set lasts for a long time, can participate in several Campaigns and have several goals.
- Malware – describes instances of malicious software.
- Observed data – describes non-malicious technical artifacts.
- Report – describes in an understandable way any threat, malicious grouping, their TTPs, and victims. It is a kind of analytical summary that allows understanding the essence of the threat, its danger, malware, techniques used, tactics and procedures used by the attacking party.
- Threat actor – describes persons, groups or organizations that act with malicious intent. In short, it concerns intruders and hackers. It is the malicious intent in the motivation of this entity that distinguishes it from Identity.
- Tool – describes legitimate software that can be used to carry out attacks. The difference between this entity and Malware is precisely that it is legitimate software, for example, nmap or RDP, VNC.
- Vulnerability – describes flaws/gaps in requirements, logic, design, implementation of software or hardware that can be exploited and negatively affect the confidentiality, integrity, or availability of the system.
The above sets of entities and relationships allow describing in an understandable way the data that can be used by the machine. This is illustrated by a couple of the following examples.
Example No. 1
This example describes the IoC http://x4z9arb.cn/4712/ of the URL type and its relation (attribution) to the x4z9arb backdoor malware. At that, it is clearly visible that the indicator is a site where the malicious downloader is located, in this case, the x4z9arb backdoor malware.
What does this mean for an analyst? It’s pretty simple: if the analyst traces of presence (indicator of compromise http://x4z9arb.cn/4712/) in the company’s infrastructure, then he can conclude that he is dealing with x4z9arb backdoor malware. The next steps usually depend on the malware that got inside the infrastructure. There are many databases for its analysis, for example, Malpedia.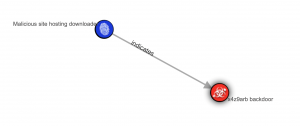
Example No. 2
This example clearly describes links between the Adversary Bravo attacker, the phishing attack technique used, and the Poison Ivy Variant d1c6 malware.
In this case, if PoisonIvy malware variant d1с6 is detected, such a feed structure with relationships will help to understand that such malware is employed be attacker.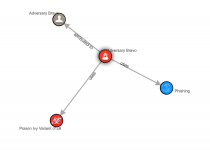
The examples given are quite trivial, but easy to understand. Analysis of complex examples can be the topic of a special article. However, for clarity, below is shown how one can pack the results of a voluminous study, such as a report on the activities of the APT1 malicious grouping (link to json) into STIX:
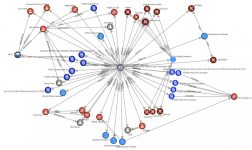
To sum up, STIX is a fairly powerful and flexible format for describing a wide variety of threats and exchanging them between different consumers. It has many advantages, such as expressiveness, that is, good descriptive ability, flexibility, and the ability to automate. Notable disadvantages may perhaps concern the consequence of the listed advantages – relatively high entry threshold, because of which STIX has not yet received the status of an “industry standard”.
MISP format
MISP[2] is a popular open-source Threat Intelligence platform. Over the years of its existence it has grown into a fairly large and active community. Since 2016, the data exchange format has been entered into the IETF in the status of internet draft, that is, it tends to become the RFC, but has not yet become one.
The concept of the MISP platform focuses primarily on the creation and p2p-exchange of threat intelligence data, that is, the main goal is creating and disseminating knowledge between various community members. The depth and width of such distribution can be flexibly adjusted by settings.
The MISP data exchange format went a slightly different way than STIX. Unlike the latter, MISP does not divide its data model into a large number of deterministic objects of different types, which are relatively few:
- Event – is some event, an incident, an analytical report that tells about something. In fact, an Event is a container.
- Event attributes – most often these are indicators of compromise, various technical artifacts. That is, Events, like containers, collect various indicators of compromise, which tell about a certain threat or malicious campaign (or about several, but semantically close threats or campaigns).
- Object – is needed to generalize attributes based on certain common ground. For example, to associate several hashes (md5, sha1. sha256) with the file name from which they were taken. Objects can be linked to each other using the proxy object, i.e. Object References.
- Tags – are markings for classification, which can be either presented as user strings, or taken from the MISP Taxonomies directory.
- Sighting – are facts about where, when, and under what conditions and by whom a particular attribute was encountered.
- Galaxy – is the connection of objects or attributes with the context, which gives a more detailed description of objects /attributes. In fact, this is an extension of the tags’ functionality. Galaxies are decomposed into Clusters and Elements. As an example, this may look like this: the attribute is tied to Threat Actor (Galaxy), MuddyWater (Element); thus, attribution is clearly understandable from this connection.
Example
From this example, it can be seen that the feed tells about two indicators of compromise –adfs.senate.group and adfs-senate.email, which are associated with the Pawn Storm malware campaign. There is a link to the primary source of the investigation – a post on Trend Micro blog.
MISP Event
MISP is a fairly extensive format that allows describing threats in sufficient detail. It has all the tools required: an abundance of attributes, taxonomies for categorization, and galaxies for clustering threats. However, as in many community-driven things, in our opinion, it lacks the harmony, determinism, typed relationships and rules for their use that are inherent in STIX. This does not mean that STIX looks definitely more advantageous – this is our humble opinion. Time and healthy competition will show whose approach will be more effective.
Other formats
Besides STIX and MISP, being great pillars in the world of threat intelligence data exchange standardization, there are many other formats. It should be noted that the largest number of open source feeds are in txt and csv formats. It is rare to find them in STIX or MISP, which I would rather call the lot of commercial, moderated, enriched, well-structured feeds. Other formats (MAEC, IODEF, CAPEC, IODEF, VERIS) are rare.
Why have txt and csv become so popular? The answer is because of their simplicity. Most open source feeds are either feeds with minimal context (tic marks, malware naming, tags), or just bare indicators of compromise without any context (just indicator values). The easiest way to package such indicators is plain text or csv, since any other formats have a higher entry threshold.
The disadvantage of plain-text feeds is the lack of context, that is, usually such feeds are sheets of IP addresses, hashes, domains, URLs, and less often – something else. The problem is that such feeds without context, bare in fact, are difficult to trust and interpret, since it is unclear what kind of threats are represented by indicators of compromise contained in them, and how relevant and malicious these threats are.
The csv feeds often contain several columns describing values, indicator type, and tic marks. Sometimes they contain descriptions of malware or exploited vulnerabilities that are associated with this indicator. In general, csv feeds, having at least some context, can be more useful. However, it depends on different situations, because it may happen that a plain-text feed with indicators on a very relevant threat for a particular industry or company may be more useful than any other feed with context.
The main problems when working with feeds in free formats such as txt and csv are the collection and reduction to a single normal form, as well as data binding. Txt can contain comments, different feeds can be in the same file and different ways of separating indicators of compromise can be used – such feeds are quite difficult to parse. In csv feeds, data extraction is also sometimes quite difficult: separators in a single file may not be consistent. This is relevant for feeds where edits are made manually. In general, the practice has shown that an unexpected event can happen at any time. A separate topic is the implicitness in linking attributes in csv. Sometimes it is quite difficult to understand which attributes relate to what.
Examples
In this example, it is clearly visible that there is one column with the indicator of compromise, one column with a malware family that is associated with a hash. Besides, there is a column with a country (although it is not entirely clear whether the country is the source of the attack or the target), another column contains a link to the study/threat report. Such a csv feed is more or less understandable.

Here is another example of a feed with an unambiguous and good description: it is clear what attributes are available and what relationships exist between them:
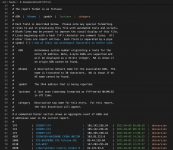
And in this example it is unclear what the date refers to: the third column (URL) or the fifth (hash)?

Here is another example: there are two columns with an indicator of compromise (url, ip), as well as a column with a date. However, it is unclear which of the indicators of compromise this date refers to, as well as what it means. Unclear is the time of the first detection of the indicator, the time of the last detection of the indicator, something different.

As can be seen from the above examples, general-purpose formats are quite suitable for publishing TI feeds, but the problem usually lies in the subsequent interpretation of these formats. This can cause significant confusion when using data in the course of applying TI, for example, when responding to incidents. In this regard, specialized STIX/MISP solve the interpretation problem much better due to the determinateness of data schemas.
A few practices of publishing feeds in outdated formats, such as for example, STIX 1.*, OpenIOC and others, are also left out of the discussion since they are really either hopelessly outdated and are no longer used, or have merged with other standards, or have evolved into newer versions that meet current requirements.
Conclusions
In the world of threat intelligence, not everything is as clear as it seems at first glance. On the one hand, a fairly active community has formed, which develops open standards that solve quite understandable problems and tasks of the majority of TI users (consumers and manufacturers). At the same time, various manufacturers of information security tools often develop and use their own formats that are most advantageous in their specific use cases. Besides, there is a practice of using general-purpose formats like txt, csv, rss, pdf.
All this clearly indicates that a single industry standard has not yet been formed in this area. Those who are not convinced by these arguments, can be addressed to several studies presented in primary sources:
- https://arxiv.org/abs/2103.03530
- https://res.mdpi.com/d_attachment/electronics/electronics-09-00824/article_deploy/electronics-09-00824-v3.pdf
The absence of an industry standard is inherently neither good nor bad, being just a fact. Sometimes it brings certain inconveniences to the TI product manufacturers, suppliers, and consumers. This is only a consequence of the fact that TI is still a relatively young field, which is a big melting pot, in which a lot of requirements from various sides have not yet found implementations that suit everyone 100%, so a kind of chaos prevails, gradually crystallizing into best practices. We think standardization is a matter of time.
From the standpoint of the TI platform, such a heterogeneity of formats is a real challenge, since one needs to collect all the data from a variety of sources, shift them into own model, not lose meaning and, if possible, lose a minimum of data – those that semantically cannot be placed in the fields of the platform’s data model. Exactly in the next article we will look in more detail at specific feeds, tell what difficulties await on the way to their collection, processing and interpretation.
Keep tuned for more!
[1] Structured Threat Information Expression (STIX) is a language and serialization format used to exchange cyber threat intelligence
[2] Malware Information Sharing Platform